

1.什么是OLLVM
OLLVM是一款针对LLVM的代码混淆工具,目的是加强逆向的难度,整个项目包含数个包含独立功能的LLVM Pass,每个Pass会对应实现一种特定的混淆方式。通过这些Pass可以改变源程序的CFG和源程序的结构。
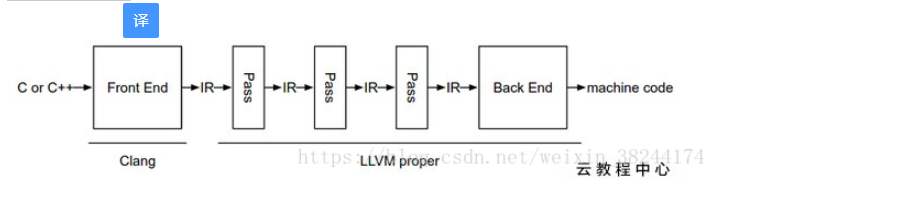
LLVM与OLLVM最大的区别在于混淆Pass的不同。混淆Pass作用于LLVM的IR中间语言 ,通过Pass混淆IR,左后后端依据IR生成的目标语言也会得到相应的混淆
2.OLLVM的三大功能
Instructions Substitution(指令替换)、Bogus Control Flow(混淆控制流)、Control Flow Flattening(控制流平展)
1)指令替换功能:随机选择一种功能上等效但更复杂的指令序列替换标准二元运算符;适用范围:加法操作、减法操作、布尔操作(与或非操作)且只能为整数类型。
操作指令:-mllvm -sub: activate instructions substitution
-mllvm -sub_loop=3: if the pass is activated, applies it 3 times on a function. Default : 1.
示例代码://替换前
a = b - (-c)
%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = sub i32 0, %1
%3 = sub nsw i32 %0, %2
//替换后
a = -(-b + (-c))
%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = sub i32 0, %0
%3 = sub i32 0, %1
%4 = add i32 %2, %3
%5 = sub nsw i32 0, %4
(2)混淆控制流功能:1.在当前基本块之前添加基本块来修改函数调用图。2.原始基本块也被克隆并填充随机选择的垃圾指令。
操作指令:-mllvm -bcf: activates the bogus control flow pass
-mllvm -bcf_loop=3: if the pass is activated, applies it 3 times on a function. Default: 1
-mllvm -bcf_prob=40: if the pass is activated, a basic bloc will be obfuscated with a probability of 40%. Default: 30
(3)控制流平展功能:目的是完全展平程序的控制流程图。我自己的理解是if...else变为switch..case..语句。
操作指令:-mllvm -fla: activates control flow flattening
-mllvm -split: activates basic block splitting. Improve the flattening when applied together.
-mllvm -split_num=3: if the pass is activated, applies it 3 times on each basic block. Default: 1
3.OLLVM环境搭建
OLLVM版本号:OLLVM 4.0;Ubuntu环境:Ubuntu16.04;虚拟机中处理器数量为4个、运行内存3G,分配硬盘空间50g。$ git clone -b llvm-4.0 https://github.com/obfuscator-llvm/obfuscator.git
$ mkdir build
$ cd build
$ cmake -DCMAKE_BUILD_TYPE=Release ../obfuscator/
$ make -j7
若是git clone一直失败,下不下来,尝试: git config --global http.postBuffer 20000000
若是cmake时一直报错,则将cmake那句替换为:cmake -DCMAKE_BUILD_TYPE=Release -DLLVM_INCLUDE_TESTS=OFF ../obfuscator/
若是make时时间太长,则重新cmake后,多分配一些内存和处理器。
4.对LLVM,clang,IR概述
LLVM就像一个编译器,一个完整的编译架构。他把源代码生成与机器码无关的中间代码(IR),然后对产生的IR进行优化,生成对应的机器汇编语言。这个与传统的编译器前段,中间优化,后端设计的模式相似。而不同之处在于,可以通过自定前端或者后端使其支持编译你的语言。
对于LLVM来说,前段是clang,在编译原码文件的时候使用的编译工具也是clang。生成中间的IR码后需要对其进行一些操作,比如添加一些代码混淆的功能。LLVM的做法就是通过编写Pass(即很多个类,每个类都有自己的功能)来实现混淆的功能。
加固与保护
VMP保护(虚拟软件保护技术)的思路是自定义一套虚拟机指令和对应的解释器。安卓系统的后端使用了LLVM,smali2c的技术已经渐渐成熟,所以OLLVM(开源的代码混淆器)变成了一个可选项,但是对于加固来说,它的保护是基于代码级别的,需要提供源代码或编译中间的代码。
5.OLLVM简单的源码分析
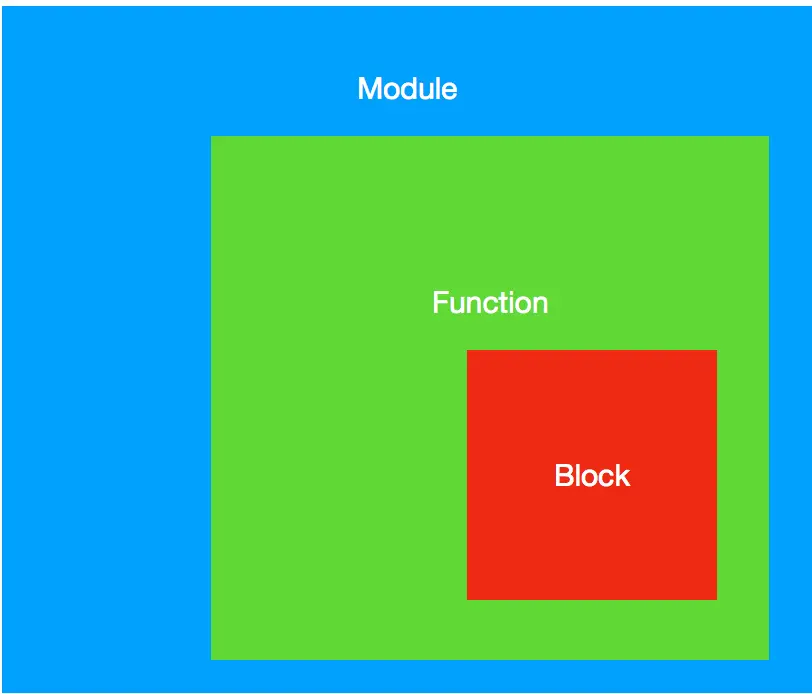
IR的基本结构:
IR代码是由一个个的Module组成的,每个之间又相互联系,Mdule又是由一个个Function组成,Function又是由一个个BasicBlock组成,在BasicBlock中又包含了一条条Instruction。
基本块的分割为例
OLLVM的每个pass,其主要的工作继承对应的pass类,就是对应的方法进行重写,如SplitBasicBlock的实现,它继承自FunctionPass,并重写了runOnFunction方法:
bool SplitBasicBlock::runOnFunction(Function &F) {
// Check if the number of applications is correct
if (!((SplitNum > 1) && (SplitNum <= 10))) {
errs()<<"Split application basic block percentage\
-split_num=x must be 1 < x <= 10";
return false;
}
Function *tmp = &F;
// Do we obfuscate
if (toObfuscate(flag, tmp, "split")) {
split(tmp);
++Split;
}
return false;
}1、SplitBasicBlock 首先对SplitNum进行判断,SplitNum定义如下:static cl::opt<int> SplitNum("split_num", cl::init(2),
cl::desc("Split <split_num> time each BB"));
这里是对用clang编译源文件的时候选用的参数split做的定义:clang -mllvm -split test.c
clang -mllvm -split_num=3 test.c
第一条指令表示启用最基本block的分割,使之扁平化:
第二条指令的作用是对基本的block分割次数为三次(前提是以启用split),默认为一次
2、对于1~10 之外的情况,提示分割次数错误,即分割次数必须在1~10次之内。
3、于符合要求的splitNum,调用toObfuscate函数进行处理,处理方式如下(该函数在Utils.h文件中):bool toObfuscate(bool flag, Function *f, std::string attribute) {
std::string attr = attribute;
std::string attrNo = "no" + attr;
// Check if declaration
if (f->isDeclaration()) {
return false;
}
// Check external linkage
if(f->hasAvailableExternallyLinkage() != 0) {
return false;
}
// We have to check the nofla flag first
// Because .find("fla") is true for a string like "fla" or
// "nofla"
if (readAnnotate(f).find(attrNo) != std::string::npos) {
return false;
}
// If fla annotations
if (readAnnotate(f).find(attr) != std::string::npos) {
return true;
}
// If fla flag is set
if (flag == true) {
/* Check if the number of applications is correct
if (!((Percentage > 0) && (Percentage <= 100))) {
LLVMContext &ctx = llvm::getGlobalContext();
ctx.emitError(Twine("Flattening application function\
percentage -perFLA=x must be 0 < x <= 100"));
}
// Check name
else if (func.size() != 0 && func.find(f->getName()) != std::string::npos) {
return true;
}
if ((((int)llvm::cryptoutils->get_range(100))) < Percentage) {
return true;
}
*/
return true;
}
return false;
}这个函数的主要功能是检查以及判断是否使用了split功能,判断依据就是Functions annotations和flag。
接下来看分割处理的函数split:
void SplitBasicBlock::split(Function *f) {
std::vector<BasicBlock *> origBB;
int splitN = SplitNum;
// Save all basic blocks
for (Function::iterator I = f->begin(), IE = f->end(); I != IE; ++I) {
origBB.push_back(&*I);
}
for (std::vector<BasicBlock *>::iterator I = origBB.begin(),
IE = origBB.end();
I != IE; ++I) {
BasicBlock *curr = *I;
// No need to split a 1 inst bb
// Or ones containing a PHI node
if (curr->size() < 2 || containsPHI(curr)) {
continue;
}
// Check splitN and current BB size
if ((size_t)splitN > curr->size()) {
splitN = curr->size() - 1;
}
// Generate splits point
std::vector<int> test;
for (unsigned i = 1; i < curr->size(); ++i) {
test.push_back(i);
}
// Shuffle
if (test.size() != 1) {
shuffle(test);
std::sort(test.begin(), test.begin() + splitN);
}
// Split
BasicBlock::iterator it = curr->begin();
BasicBlock *toSplit = curr;
int last = 0;
for (int i = 0; i < splitN; ++i) {
for (int j = 0; j < test[i] - last; ++j) {
++it;
}
last = test[i];
if(toSplit->size() < 2)
continue;
toSplit = toSplit->splitBasicBlock(it, toSplit->getName() + ".split");
}
++Split;
}
}该函数首先定义了一个vector数组origBB用于保存所有的block块,然后遍历origBB,对每一个blockcurr,如果它的size(即包含的指令数)只有1个或者包含PHI节点,则不分割该block。 对于待分割的block,首先生成分割点,用test数组存放分割点,用shuffle打乱指令的顺序,使sort函数排序前splitN个数能尽量随机。 最后分割block是调用splitBasicBlock函数分割基本块。
下面来细致看一下OLLVM的一些功能:
1.指令的切割功能
实现于SplitBasicBlock.cpp中,继承自FunctionPass,并重写了runOnFunction方法。
第一步:判断切割次数是否符合OLLVM的要求,即splitNum分割次数必须在10以内
第二部:对于符合要求的splitNum,调用toObfuscate函数进行处理。主要是各种检查以及判断是否启用了split功能,依据就是Functions annotations和flag。
bool SplitBasicBlock::runOnFunction(Function &F) {
// Check if the number of applications is correct
if (!((SplitNum > 1) && (SplitNum <= 10))) {
errs()<<"Split application basic block percentage\
-split_num=x must be 1 < x <= 10";
return false;
}
Function *tmp = &F;
// Do we obfuscate
if (toObfuscate(flag, tmp, "split")) {
split(tmp);
++Split;
}
return false;
}..........
(与上面的情况相似)
2.指令替换功能
实现于Substitution.cpp中,同样继承自FunctionPass,并重写了runOnFunction方法。
第一步:调用toObfuscate函数进行处理,进入substitute方法后,这个方法可以看到,OLLVM只对加、减、与。异或五种操作进行替换,funcXXX变量都是函数数组,随机的选择一种变换进行操作。ObfTimes对应的是指令切割次数:-sub_loop。
bool Substitution::substitute(Function *f) {
Function *tmp = f;
// Loop for the number of time we run the pass on the function
int times = ObfTimes;
do {
for (Function::iterator bb = tmp->begin(); bb != tmp->end(); ++bb) {
for (BasicBlock::iterator inst = bb->begin(); inst != bb->end(); ++inst) {
if (inst->isBinaryOp()) {
switch (inst->getOpcode()) {
case BinaryOperator::Add:
// case BinaryOperator::FAdd:
// Substitute with random add operation
(this->*funcAdd[llvm::cryptoutils->get_range(NUMBER_ADD_SUBST)])(
cast<BinaryOperator>(inst));
++Add;
break;
case BinaryOperator::Sub:
// case BinaryOperator::FSub:
// Substitute with random sub operation
(this->*funcSub[llvm::cryptoutils->get_range(NUMBER_SUB_SUBST)])(
cast<BinaryOperator>(inst));
++Sub;
break;
case Instruction::AShr:
//++Shi;
break;
.....
break;
} // End switch
} // End isBinaryOp
} // End for basickblock
} // End for Function
} while (--times > 0); // for times
return false;
}第二步:以下代码对应着funcAdd数组的四种替换方法的实现。 (1)将第二个操作数取反,然后改写成减法指令。
(2)将两个操作数都取反,结果相加之后再次取反。
(3)取一个随机数,将随机数与操作数1相加,然后将结果与操作数2相加,最后减去随机数。
(4)取一个随机数,将操作数1减去随机数,然后将结果与操作数2相加,最后加上随机数。
// Implementation of a = b - (-c)
void Substitution::addNeg(BinaryOperator *bo) {
BinaryOperator *op = NULL;
// Create sub
if (bo->getOpcode() == Instruction::Add) {
op = BinaryOperator::CreateNeg(bo->getOperand(1), "", bo);
op =
BinaryOperator::Create(Instruction::Sub, bo->getOperand(0), op, "", bo);
// Check signed wrap
//op->setHasNoSignedWrap(bo->hasNoSignedWrap());
//op->setHasNoUnsignedWrap(bo->hasNoUnsignedWrap());
bo->replaceAllUsesWith(op);
}/* else {
op = BinaryOperator::CreateFNeg(bo->getOperand(1), "", bo);
op = BinaryOperator::Create(Instruction::FSub, bo->getOperand(0), op, "",
bo);
}*/
}
......1 替换
1.1 Add
| 变换前 | 变换后 |
|---|---|
| a=b+c | a=b-(-c) |
| a=b+c | a= -(-b + (-c)) |
| a=b+c | r = rand (); a = b + r; a = a + c;a = a – r |
| a=b+c | r = rand (); a = b - r; a = a + b; a = a + r |
1.2 Sub
| 变换前 | 变换后 |
|---|---|
| a=b-c | a=b+(-c) |
| a=b-c | r = rand (); a = b + r; a = a - c;a = a – r |
| a=b-c | r = rand (); a = b - r; a = a -c;a = a + r |
1.3 And
| 变换前 | 变换后 |
|---|---|
| a=b&c | a=(b^~c)&b |
| a=a&b | !(!a | !b) & (r | !r) |
1.4 Or
| 变换前 | 变换后 |
|---|---|
| a=b|c | a=(b&c)|(b^c) |
| a|b | [(!a & r) | (a & !r) ^ (!b & r) |(b & !r) ] | [!(!a | !b) & (r |!r)] |
1.5 Xor
| 变换前 | 变换后 |
|---|---|
| a=a^b | a = (!a & b) | (a & !b) |
| a=a^b | (a ^ r) ^ (b ^ r)或(!a & r | a & !r) ^ (!b & r | b & !r) |
1.6 命令
| 命令 | 解析 |
|---|---|
| -mllvm -sub | 激活指令替换 |
| -mllvm -sub_loop=3 | 若已被激活,进行3次替换,默认为1 |
2
| 命令 | 解析 |
|---|---|
| -mllvm -sub | 激活指令替换 |
| -mllvm -sub_loop | 若激活了指令替换,在函数中应用指令替换的次数 |
3.控制流平坦功能:
实现于Flattening.cpp中,同样继承自FunctionPass,并重写了runOnFunction方法。
第一步:判断是否可以平展,如果可以,则跳入flatten方法中执行。在函数开始的时候使用LowerSwitchPass去除switch,将switch结构换成if结构。保存所有的基本代码块,如果只有一个基本代码块,则不进行处理;如果第一个基本代码块的末尾是跳转指令,那么需要它分割开来,并且将它保存到origBB; // Lower switch
FunctionPass *lower = createLowerSwitchPass();
lower->runOnFunction(*f);
第二步:创建两个基本块,存放循环头和尾的指令,然后就把first bb移到loopEntry的前面,并且创建一条跳转指令,从first bb跳到loopEntry。紧接着创建了一条从loopEnd跳到loopEntry的指令。最后,创建了switch指令和switch default块,并且创建相应的跳转。
// Create main loop
loopEntry = BasicBlock::Create(f->getContext(), "loopEntry", f, insert);
loopEnd = BasicBlock::Create(f->getContext(), "loopEnd", f, insert);
load = new LoadInst(switchVar, "switchVar", loopEntry);
// Move first BB on top
insert->moveBefore(loopEntry);
BranchInst::Create(loopEntry, insert);
// loopEnd jump to loopEntry
BranchInst::Create(loopEntry, loopEnd);
BasicBlock *swDefault =
BasicBlock::Create(f->getContext(), "switchDefault", f, loopEnd);
BranchInst::Create(loopEnd, swDefault);
// Create switch instruction itself and set condition
switchI = SwitchInst::Create(&*f->begin(), swDefault, 0, loopEntry);
switchI->setCondition(load);
......
第三步,删除first bb的跳转指令,改为跳转到loopEntry,将所有的基本块加入switch结构.接下来是根据原先的跳转来计算switch变量。
(1)若为没有后继(return BB)的基本块,直接跳过。
(2)若为只有一个后继的基本块,首先删除跳转指令,并且通过后继基本块来搜索对应的switch case,根据case创建一条存储指令,达到跳转的目的。
(3)两个后继的情况跟一个后继的处理方法相似,不同的是,创建一条select指令,根据条件的结果来选择分支。
还有一个虚假控制流的功能展示没看
Comments | NOTHING